Comment influence l’algorithme de Linkedin ? Quelle est la corrélation entre le nombre de likes ou commentaires, et le nombre de vues dans Linkedin ?
Tout le monde cherche à comprendre l’algorithme de Linkedin. Certains essayent même de le hacker.
Si les hypothèses fleurissent, personne ne sait vraiment comment ça marche. Je me suis retroussé les manches et aujourd’hui je vous explique, modèle statistique à l’appui.
BONUS : recevez votre analyse statistique personnelle
Je vous propose de réaliser la même analyse pour votre activités Linkedin. Inscrivez-vous à la newsletter ci-dessous et vous recevrez un email contenant des instructions pour que je puisse vous aider. Il est probable que j’organise également un webinar pour vous montrer la méthode. Si vous voulez être tenu au courant, inscrivez-vous là aussi à la newsletter (n’oubliez pas de valider l’email de confirmation que vous recevrez après avoir entré voir adresse).
Si vous n’avez que 30 secondes
- j’ai constitué « à la main » un jeu de données comprenant toutes mes publications Linkedin des 17 derniers mois
- des métadonnées ont été générées pour chaque publication (présence d’un hyperlien, photos, …)
- en 1ère approximation je n’ai pas pris en compte d’autres variables (présence d’un hyperlien par exemple)
- l’analyse est propre à chacun et dépend de la taille et de la composition de votre réseau.
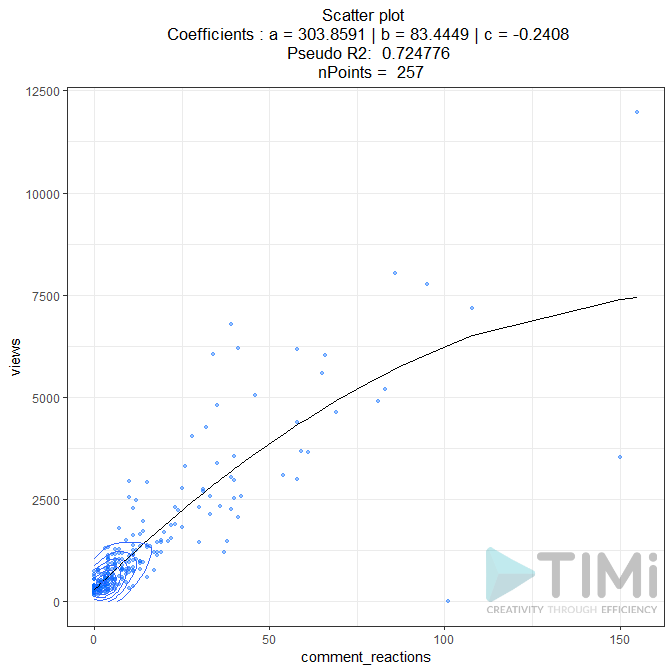
- une analyse statistique menée avec Anatella et Tableau montre que chaque réaction/commentaire rapporte 83 vues sur Linkedin
- Lorsque vous ne récoltez aucun like ou commentaire, votre post Linkedin stagne à environ 300 vues
- Si vous voulez savoir comment agit l’algorithme sur VOTRE réseau, envoyez-moi un email (ou une demande de connexion Linkedin 🙂 pour que je puisse vous aider
Sommaire

Introduction

 L’algorithme de Linkedin reste un peu mystérieux. Une hypothèse courante consiste à dire que le nombre de réactions (like, curiosité, … voir ci-contre) attribuées dans les 2 premières heures de publication est crucial pour rendre la publication virale. Depuis la mise à jour de l’algorithme toutefois, cette hypothèse pourrait être remise en cause.
L’algorithme de Linkedin reste un peu mystérieux. Une hypothèse courante consiste à dire que le nombre de réactions (like, curiosité, … voir ci-contre) attribuées dans les 2 premières heures de publication est crucial pour rendre la publication virale. Depuis la mise à jour de l’algorithme toutefois, cette hypothèse pourrait être remise en cause.
Les hypothèses restent donc générales et aucune étude n’a été faite sur l’effet propagateur des réactions et commentaires. En d’autres termes, combien de personnes supplémentaires sont susceptibles d’être touchées quand quelqu’un réagit ou commente votre post Linkedin ?
C’est ce que je vais vous révéler dans l’article d’aujourd’hui.
Focus sur Anatella
Anatella est un de mes outils « data » préférés (si vous voulez des renseignements ou une démo, envoyez-moi un petit mail) et en plus il est gratuit pour les petites entreprises. Il s’agit d’une solution d’ETL (Extract – Transform -Load) qui permet de manipuler de grandes quantités de données facilement pour les analyser. Grâce à une superbe intégration avec R, il est en outre très simple de réaliser des analyses statistiques sans avoir à coder dans R. Ça m’arrange bien car même si j’ai appris à développer en R, le manque de pratique vous fait tout oublier très vite.
Méthodologie

Pour constituer le dataset je suis remonté aussi loin que possible dans mes posts afin de relever :
- le nombre de vues
- les variables caractérisant le post (présence d’un hyperlien, d’une photo, d’une vidéo, le texte du post, les hashtags, …)
J’ai réussi à collecter 17 mois d’historique.
Le dataset final consiste en 257 posts, répartis sur 17 mois, codés suivant 17 variables. Au final nous avons donc un petit dataset contenant 4369 points. C’est petit mais l’effort (manuel) pour constituer ce dataset est assez important (environ 10 heures de travail).
Pour l’analyse j’ai utilisé Anatella pour la préparation des données, Tableau Software pour la visualisation des données, et R pour les analyses statistiques (via une intégration dans Anatella).

La préparation des données est réalisée grâce à un flow très simple (voir ci-dessus) dans lequel j’ai nettoyé les données, éliminé les champs vides, et ai créé une variable « comment_reactions » qui est la somme du nombre de réactions et du nombre de commentaires.
Différents types de modèles simples ont été testés pour modéliser le nombre de vues (variable dépendante). Un modèle polynomial donnait les meilleurs résultats.

Résultats
Voici la partie que vous attendez tous. Quel est le lien entre le nombre de réactions / commentaires et le nombre de vues ?
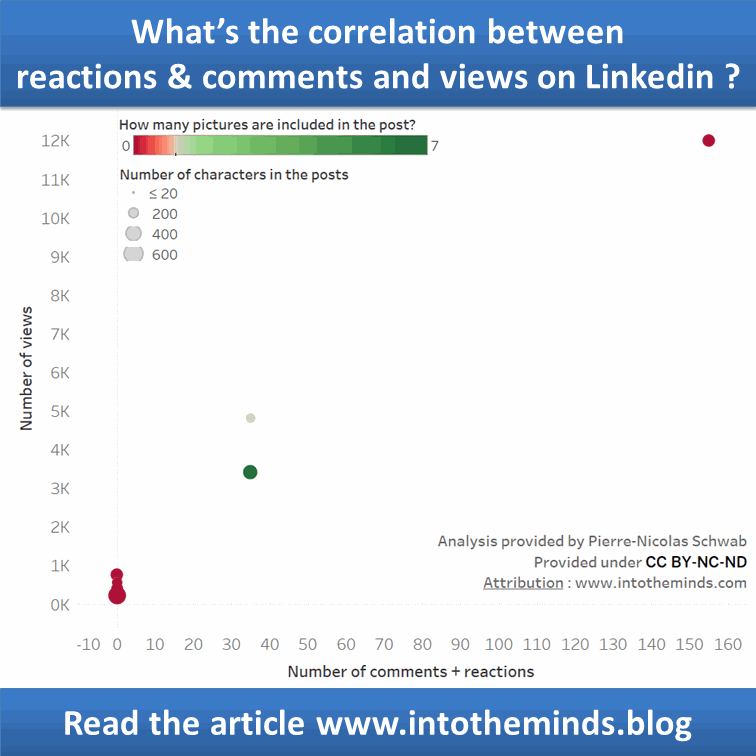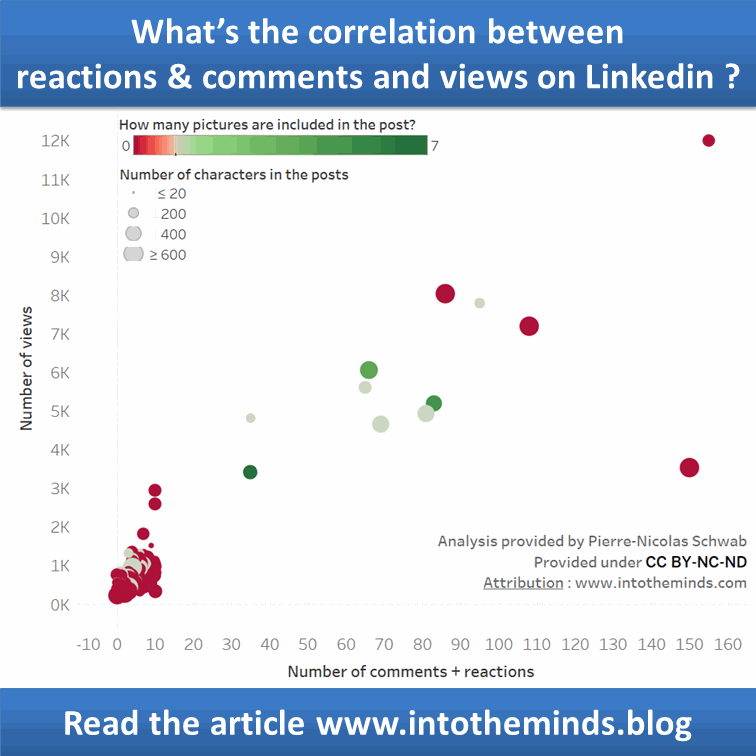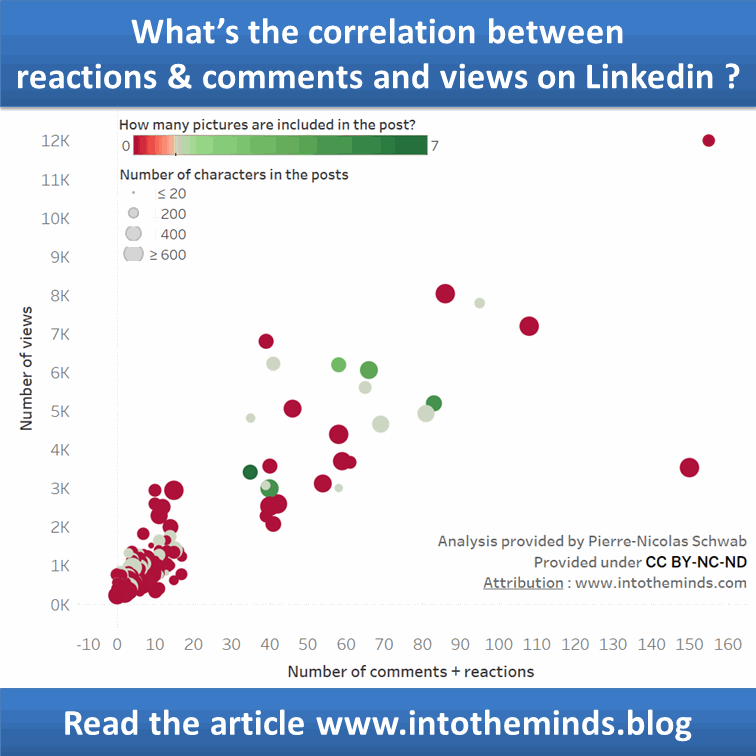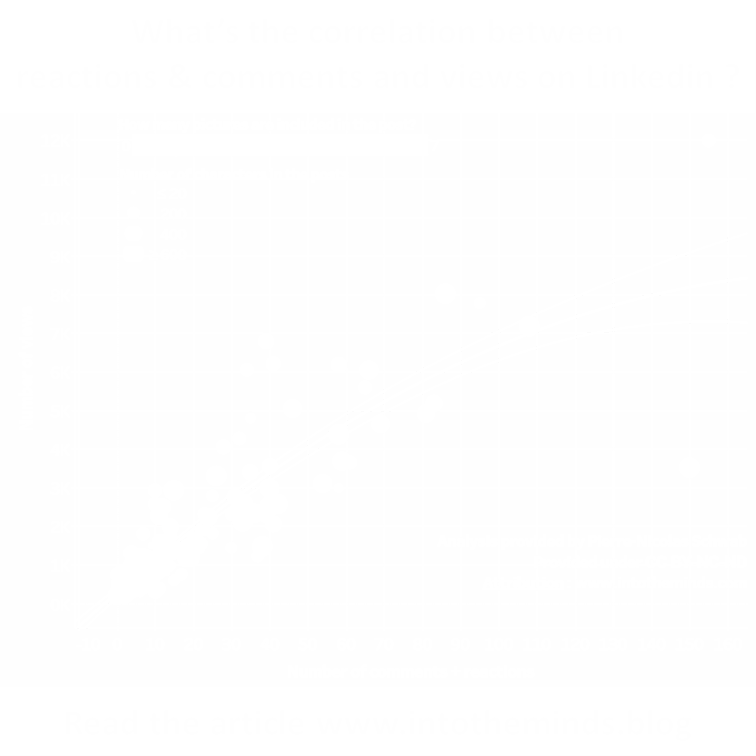
Le graphique ci-dessous vous montre le résultat de la modélisation. Vous voyez que même sans like ni commentaire, une publication devrait toujours atteindre 303 personnes. Chaque like ou commentaire apporte un incrément de 83 vues supplémentaires. Au-delà de 100 likes+commentaires, le modèle marque une inflexion qui est surtout due à l’absence de points de mesure (seulement 2).
La courbe de tendance tracée dans Tableau donne en gros le même résultat (Tableau indique un R² de 0,78; Anatella un pseudo-R² de 0,72).
J’ai rajouté dans la visualisation sous tableau quelques dimensions supplémentaires : présence de photo dans le post : rouge en l’absence de photos, vert quand le nombre de photo est >1
La taille des points de mesure représente le nombre de caractères du post Linkedin. Plus la « bulle » est grande, plus le post Linkedin était long.

Limitations
Les effets de réseau ne sont pas pris en compte dans cette étude. La date et l’heure de publication ne le sont pas non plus car le « timestamp » des publications n’est pas disponible.
Il y a peu de points de mesure pour les grandes valeurs de vues. Il est donc nécessaire d’augmenter la taille du jeu de données avec des publications très populaires (virales) pour remodéliser l’ensemble.
L’analyse ne concerne qu’une seule personne (moi) ce qui est bien entendu la limitation la plus importante. Si vous souhaitez contribuer à cet effort de recherche, contactez-moi et je ferai l’analyse statistique.